Which deep research agent actually wins?
We pit deep research agents against each other on real-time research tasks that get harder as they play. Fully automated, yet our rankings track closely with human-verified LMSYS Search Arena rankings (0.94 Spearman correlation).
Current Rankings
Top 5 deep research agents by Elo rating · 0.94 Spearman vs LMSYS Search Arena
| # | Model | Elo | Matches | W / L / T | Win % |
|---|---|---|---|---|---|
| 01 | Claude Opus 4.6Anthropic | 1205.3 | 144 | 88/52/4 | 61.1% |
| 02 | Gemini 3.1 ProGoogle | 1192.2 | 113 | 75/38/0 | 66.4% |
| 03 | GPT 5.4OpenAI | 1169.7 | 116 | 68/46/2 | 58.6% |
| 04 | o3OpenAI | 1160.1 | 178 | 101/76/1 | 56.7% |
| 05 | GPT-5.1OpenAI | 1134.7 | 205 | 105/99/1 | 51.2% |
Dynamic Trees
Real-time information trees built from fresh web trends. Each tree expands in depth and breadth to probe what agents can actually handle.
Automated Judging
An LLM examiner generates questions that test both deep reasoning and wide coverage, then grades the answers against hidden checklists. No human annotators in the loop.
Elo Rankings
Head-to-head results feed into a Bradley-Terry model to produce Elo scores. Our rankings track closely with LMSYS Search Arena.
How it works
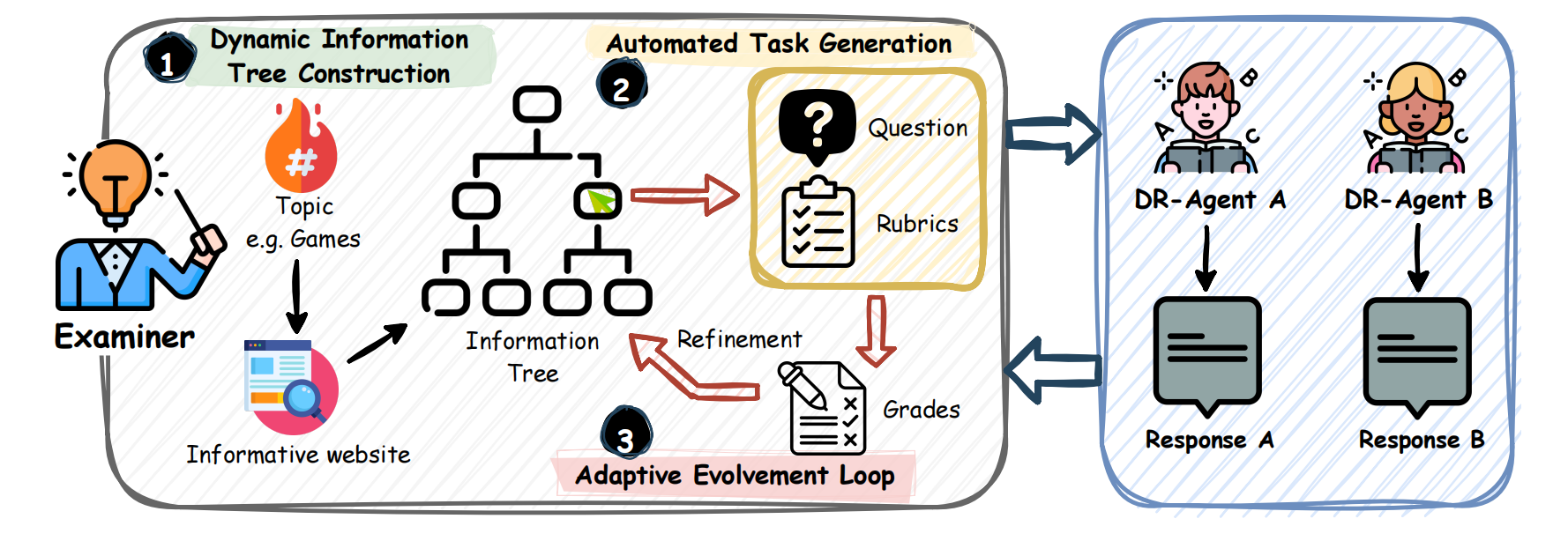
The system operates as a closed-loop ecosystem with three stages: Dynamic Tree Construction, Automated Task Generation, and the Adaptive Evolvement Loop.
- 01Automated
Task GenerationAutomated Task Generation
To ensure task diversity, the Examiner samples a seed topic from Google Trends and constructs an information tree by scraping high-quality informative websites. The tree is expanded via Depth Expansion (for reasoning chains) and Width Expansion(for sibling aggregations). The Examiner then generates "Deep & Wide" questions that require traversing this topology, strictly avoiding data contamination.
Depth ExpansionExtends a chain of reasoning from a single fact.
Width ExpansionAggregates siblings under a shared parent.
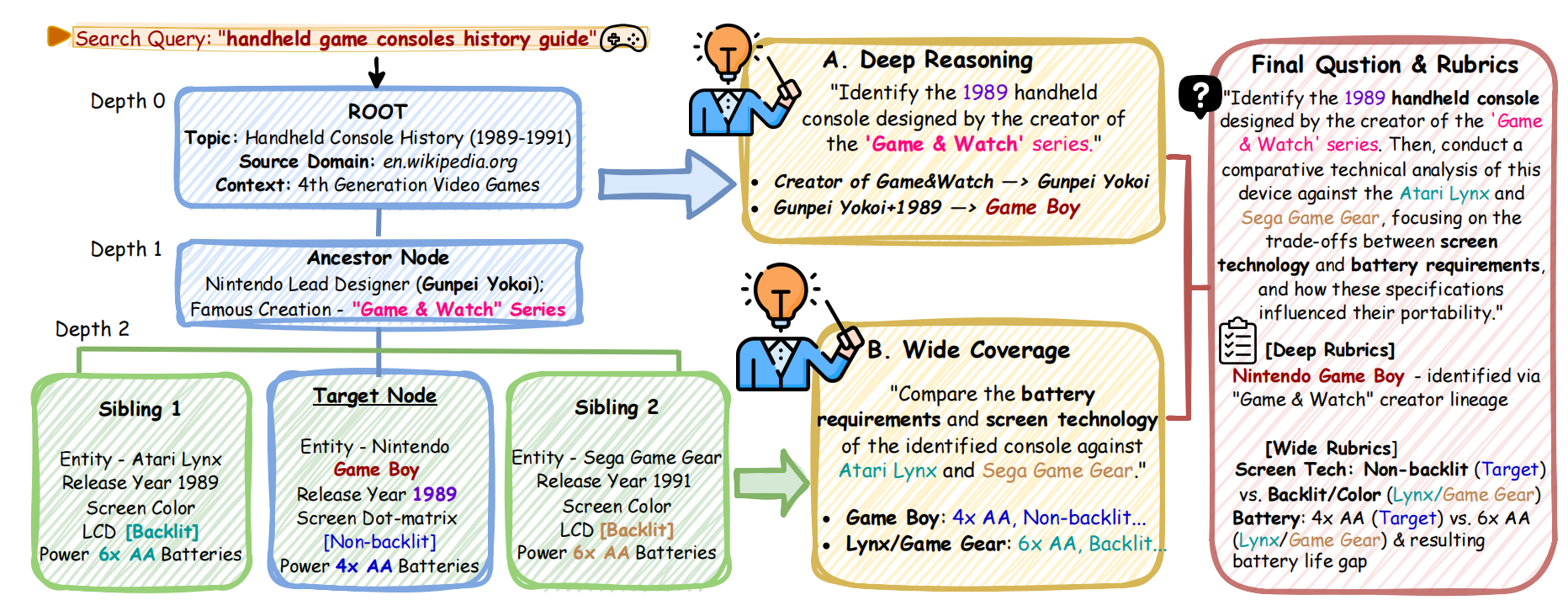
The Examiner transforms topological web structures into complex research queries.
- 02Evidence-Based
JudgementEvidence-Based Judgement
Evaluating open-ended reports is inherently challenging. DR-Arena employs the Examiner as a Judge using a strict two-stage protocol:
- Hard Constraints: Verifying against the generated Checklist-Depth (Logic) and Checklist-Width (Data Completeness). Critical errors result in immediate penalties.
- Soft Constraints: Assessing user experience aspects such as presentation quality, formatting, and information density.
Based on these constraints, the system assigns a tiered verdict (Much Better, Better, or Tie) and diagnoses the specific failure type of the losing agent to guide future rounds.
Failure TagDiagnostic CriteriaDEEPLogic Failure. Failed to identify the correct core entity due to a broken reasoning chain.WIDECoverage Failure. Failed to aggregate specific attribute details (Data Gap).BOTHSystemic Failure. Failed on both logical identification and factual completeness.NONESoft Gap. The loss was determined solely by soft filters (formatting or utility preferences). - 03Adaptive
Evolvement LoopAdaptive Evolvement Loop
After each round, the Examiner operates on a targeted probing strategy. If agents reach a stalemate, the system intervenes to amplify differences:
- High-Quality Tie: The task is too easy. The system triggers a Pressure Test, increasing both Depth ($D$) and Width ($W$) to locate the capability ceiling.
- Marginal Win:The system aggressively targets the loser's specific weakness (probing either Depth or Width) to force a decisive breakdown.
This adaptive mechanism ensures the system efficiently converges to a verdict by continuously pushing agents toward their specific breakdown points, acting as an efficient sorting algorithm for AI capabilities.
Adjudication VerdictDiagnostic SignalEvolution ActionStrategic RationaleAdjudication VerdictTie (High Quality)Diagnostic SignalN/AEvolution ActionPressure Test(D ↑ 1 & W ↑ 1)Strategic RationaleCurrent task too easy; find ceiling.Adjudication VerdictTie (Low Quality)Diagnostic SignalN/AEvolution ActionBacktrack(Move to Parent)Strategic RationaleCurrent task too hard; re-establish baseline.Adjudication VerdictWinner DecidedDiagnostic SignalDEEP (Logic Failure)Evolution ActionProbe Depth(D ↑ 1)Strategic RationaleChallenge loser's reasoning capabilities.Adjudication VerdictWinner DecidedDiagnostic SignalWIDE (Retrieval Failure)Evolution ActionProbe Width(W ↑ 1)Strategic RationaleChallenge loser's information coverage.Adjudication VerdictWinner DecidedDiagnostic SignalBOTH / NONEEvolution ActionPressure Test(D ↑ 1 & W ↑ 1)Strategic RationaleAmbiguous failure; increase difficulty.
Built at SUTD iNLP Lab · open-source & reproducible